
This requires Admin or Data Admin privileges for implementation.
Please Note: If you do not have the correct privileges to access Data Hub you will receive the following upon your login attempt. If you get this message and think it is an error please see your organization's iDashboards Administrator for assistance as Support is unable to give you access.

To help prevent Java Heap error messages using the following process will help to maintain a smooth running system.
Creating a large data load job
We will be working backward a bit to start with for this solution, so following these steps will be very important.
- From the Data Set Tab select New Data Set
- Choose Cloud API
- Pick the API you want to work with
- For this example select Objects
- Select an Object from the list to work with.
- Field: Add the fields you want to pull into your Data Set (you will need a created date, a last modified date and a unique ID field).
- Optional Related Fields: Select any fields you want to include in your data.
- Filters: Click Parameters at the bottom left of the page and then the + button to add a simple input parameter. This will act as a row limiter so we are not trying to pull and process excessively large amounts of data in one batch.

- Name: CreatedDate
- Label: Created Date
- Data Type: Datetime
- Required: Checked
- Save
- Create a second Parameter
- Name: TopCreatedDate
- Label: Created Date
- Data Type: Datetime
- Required: Checked
- Save
- Add the filters by click the Plus Icon in the bottom right of the page.
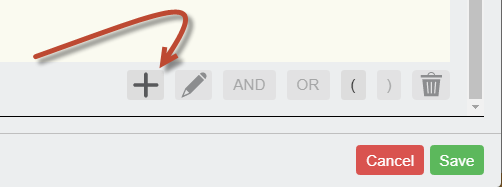
- We now need to configure the variables with selecting the 3 logic operator values:

- Choose Created Date for the Column, >= for the Logic Operator, and enter ${param:createddate} in the empty criteria field at the bottom. Click Save.
- Click the AND button to add an AND to the filter.
- Click the + to add a second filter, choose the same Column as above, select <= for the logic operator and enter ${param:topcreateddate} in the criteria field. Click Save.
- You should now see the following under the Specify Filters area.

- Save your new filter
- Save the Data Set
- Having a standard folder structure helps recalling the jobs later and what connection types are used.
- Create a Folder with your API Name then create a sub directory named Bulk Loads and save the data set in that.
- Naming Jobs: Short API name, Type of connection - Table - Short Description
- E.g. SFobj - Account - Created Date Filtered for Batch
ETL - Setup
- Create a new ETL Job
- Pull the Extract icon ("E") to the stage
- Use the configure gear to select the Data Set we just created.
- Select the Data Set we just created
- We have to fill in the parameter values for the Data Set. Use ${currdate +1} for both values. (We don't want to pull data, we're just creating the tables at this time.)
- Save
- Drag the Load icon ("L") to the stage.
- Using the vertical pointing arrow on the Extract Data task connect it to the your new Load Data into Table task.

- On the Load Data into Table task click the configuration gear.
- select the option Create a Target Table from Input
- Select your Data Store
- Select your Schema
- You will See the columns in your data now. Scan the page and look for anything you want to remove or alter. Enter The Table name and click Create.
- The Load Data into Table window now appears, I recommend checking Truncate Long Strings to Fit
- For Load Mode select Insert New Rows Only
- Check the boxes that appear under Update Key. With any Load Mode that is creating or updating rows, you will need to set a Update Key to find your data key. The data key is a unique column that appears in every row. Most of the time they are an ID column. NOTE: the Update Key can never be NULL and must be unique
- Save
- Using the vertical pointing arrow on the Extract Data task connect it to the your new Load Data into Table task.
- Save your ETL Job, you will need to name the job.
- E.g. Tablename - Batch Load
Max Data Source
This can be used for both batch loads and incremental loads. This job will be kept for the long term.
- From the top menu select Data Sets > New Data Set
- Select Custom Query from the left side
- On the Right Side of the New Data Set window, select your schema and find the target table we created previously
- Using the custom SQL builder pull the Created Date and Modified date columns onto the stage. They should go into the query where they belong.
- Now to your date field we need to add MAX. (This will return the Max Date for these values)
- If you have spaces in your column name you will need to add square brackets around the column name. [Created Date]
- The format for max is MAX([Column Name]) as MAXColumnName this is a good time to remove the spaces. It will save you some steps later.
- E.g. SELECT MAX([Created Date]) as MaxCreatedDate, MAX([Last Modified Date]) as MaxLastModifiedDate FROM YourTableName
- Press the Retrieve Columns button to test your SQL.
- Once confirmed Save - Give the Data Set a name
- E.g. MaxDates - TableNameobj Table
- Its recommended to create a folder for these Data Sets
First Date Entry in API
This section is optional but recommended. We are going to use our data source to find the first entry of data in for the table.
- Create new Data Set
- Choose our API Connection we are working with
- Query Type select SQL or Custom query
- On the right find your table expand the table now you can search for date and you should find the created date. Drag Created Date and the table name to the stage.

- Now we need to order the data and limit the rows returned.
- Salesforce: order by CreatedDate asc This will order the data in way we need.
- add Limit 1 to the end
- SELECT CreatedDate FROM TableName order by CreatedDate asc limit 1
- Salesforce: order by CreatedDate asc This will order the data in way we need.
- Save
- Save Data Set and Name
- E.g. soql - TableName- Find First Date
Back to our ETL Job
- Edit ETL Job
- Load our ETL we created
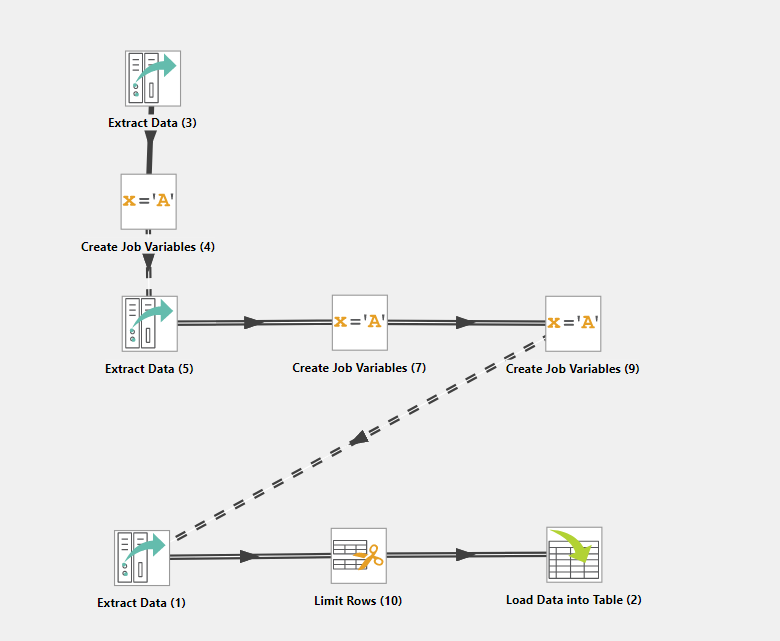
- All we have on our stage should be our Extract Data and Load Data into Table.
- Pull an Extract Icon to the stage.
- Use the configure gear
- select the Data Set we created to find the fist created date in our API table.
- Save
- Pull the Transform Icon to the stage
- Select Create Job Variables
- Attach the Extract Data task to the Create Job Variables Transformation
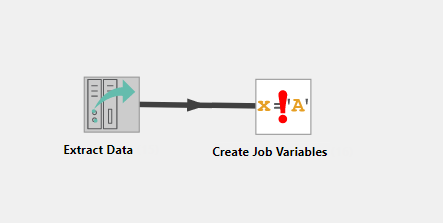
- Use the configure gear
- In the bottom right click Add
- Now we are going to create and name a Variable
- Name: SF_CreatedDate
- Type: An Expression
- Data Type: DateTime
- $first["CreatedDate"] we should only ever have 1 row returned from our query
- Create
- Pull the Extract Icon to the stage
- Connect our Job Variables task to our new Extract Data task.
- Select our Max Date Data Set.
- Save
- Pull the Transform Icon to the stage
- Select Create Job Variables
- Attach extracted Date Max Loads to this new Variables
- Use the configuration gear
- Add
- Name: myCreatedDate
- Type: An Expression
- Data Type: DateTime
- Our Expression will need an IF statement to fine the most current date to use for our job. if(new Date($first["MaxCreatedDate"]) < new Date(SF_CreatedDate)){
SF_CreatedDate;
} else {
$first["MaxCreatedDate"]
} - Create
- Add
- Name: addDays
- Type: A Fixed Value
- Data Type: Number
- Value: 180 Note: Depending on your data size change this value. Less days if the job is taking a long time to finish.
- Create
- Add
- Select Create Job Variables
- Pull the Transform Icon to the stage
- Select Create Job Variables
- Attach previous Transform task to this new Variables
- Use the configuration gear
- Add
- Name: MaxPullDate
- Type: An Expression
- Data Type: Datetime
- var sliceSizeInMillis = ( 1000 * 60 * 60 * 24 * addDays);
new Date( myCreatedDate.getTime() + sliceSizeInMillis); This take your last created date returned and adds the value setup in the previous job as addDays so that will give you the Max Date to pull. - Create
- Save
- Add
- Select Create Job Variables
- Connect our Last Created Job Variables to our fist Extract
- Use the configuration gear on Extract Job 1
- Under Data Set Parameters we need to replace our ${currdate +1} values
- Max Created Date: ${jv:myCreatedDate}
- Top Date: ${jv:MaxPullDate}
- Save
- Under Data Set Parameters we need to replace our ${currdate +1} values
- Use the configuration gear on Extract Job 1
- Save your ETL Job again.
Incremental Data Loads
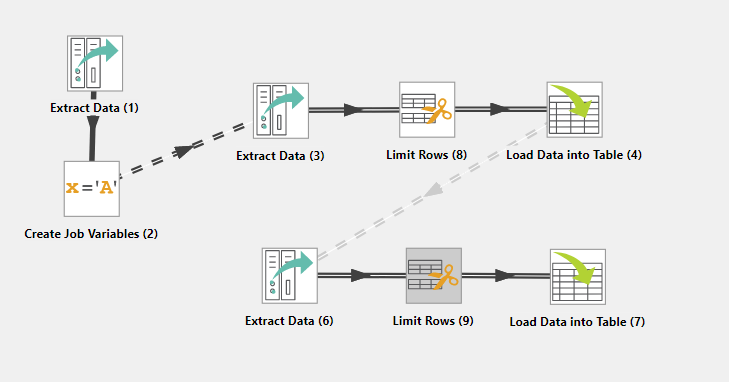
To do an incremental Load you need to have data already populated into your table.
Max Data Source
This can be used for both batch loads and incremental loads. This job will be kept for the long term.
- From the top menu select Create a new Data Set
- select your newly created database the choose Custom Query
- On the Right Side of the stage select your schema and find your target table data store
- Using the custom SQL builder pull the Created Date and Modified date columns onto the stage. They should go into the query where they belong.
- Now to your date field we need to add MAX. (This will return the Max Date for these values)
- If you have spaces in your column name you will need to add square brackets around the column name. [Created Date]
- The format for max is MAX([Column Name]) as MAXColumnName this is a good time to remove the spaces. It will save you some steps later.
- E.g. SELECT MAX([Created Date]) as MaxCreatedDate, MAX([Last Modified Date]) as MaxLastModifiedDate FROM YourTableName
- Press the Retrieve Columns button to test your SQL.
- Once confirmed Save - Give the Data Set a neme
- E.g. MaxDates - TableNameobj Table
- Its recommended to create a folder for these Data Sets
Create Max Created Date Data Set
- From the top menu select Create a new Data Set
- Select the Cloud API and choose your object
- Fields: Select the fields you want to work with (you will need a created date, a last modified date and a unique ID field).
- Related Fields (optional): add any fields you want to work with
- Add a Parameter
- Name: maxcreateddate
- Lable Max Created Date
- Data Type: Datetime
- Required: Checked
- Save
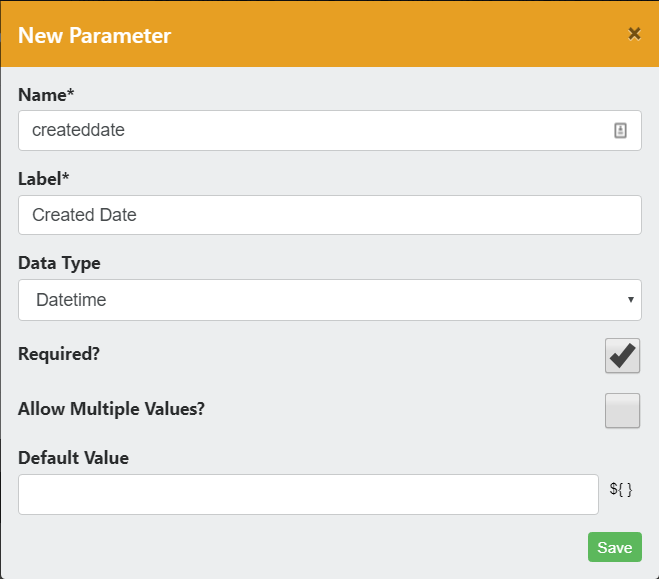
- Click the Plus icon
 in the bottom right of the screen to add a filter.
in the bottom right of the screen to add a filter.
- Search for and select created date.
- select your logic operator >
- use ${param:maxcreateddate}
- Save
- Save
- From the top menu select Create a new Data Set
- Select your object we have been working with
- Fields: Select the fields you want to work with (should be the same as last)
- Related Fields (optional): add any fields you want to work with
- Add a Parameter
- Name: maxcreateddate
- Lable Max Created Date
- Data Type: Datetime
- Required: Checked
- Save
- Click the Plus icon in the bottom right of the screen to add a filter.
- Search for your created date and select created date once found
- select your logic operator >
- use ${param:maxcreateddate}
- Save
- Save
- Name your Data Set
- Name this with created at the end E.g. SFobj_Accounts_Created
- From the current data set click Save AS
- This will ask you to Name this Data Set
- Add Modified to the end of the job name
- Click the blue Configure button in the middle right of the screen.
- Go all the way to the bottom and click Parameter
- Click the Pencil Icon
- Change the name: lastmoddate
- Lable: Last Modified Date
- Save
- Close the Parameter window
- Editing the Filter: Click the pencil in the bottom right
- Change The filter from created date to the Last Modified Date
- logic operator >
- Delete the macro in the macro field
- Use ${param:lastmoddate}
- Save
- Save
Creating the ETL Job
- From the ETL tab click New ETL Job
- Pull the Extract icon ("E") to the stage
- Use the configure gear to select the Data Set Max Dates.
- Save
- Pull the Transfrom ("T") to the stage
- Select Create Job Variables
- Connect the Extract to the Create Job Variable
- Click the gear on Create Job variable
- Click Add
- Name: MaxDateMod
- Type: Expression
- Data Type: Datetime
- From Variables select $first["CreatedDate"] (we should only return one row so first or last doesn't matter)
- Create
- Save
- Click Add
- Pull the Extract icon ("E") to the stage
- Use the configure gear to select the Data Set for the Modifications..
- Open
- On the right side you should see ${} click that icon and go to job Variables and select ${jv:MaxDateMod}
- Save
- Drag the Load icon ("L") to the stage
- Using the vertical pointing arrow on the Extract Data task connect it to the your new Load Data into Table task. (Note: If you previously created a new table in the steps above, you will link to that table instead).
- Click the Gear icon on Lad Date into table
- Select Create a Target Table from Input
- select your data store
- select your schema
- enter table name
- Load Mode: Update Existing Rows Only
- Select your ID field - NOTE: the Update key can never be NULL and must be unique
- Check Truncate Long Strings to Fit
- Save
- Pull the Extract icon ("E") to the stage
- Use the configure gear to select the Data Set for the Created Date.
- Open
- On the right side you should see ${} click that icon and go to job Variables and select ${jv:MaxDateMod}
- Save
- Drag the Load icon ("L") to the stage
- Using the vertical pointing arrow on the Extract Data task connect it to the your new Load Data into Table task.
- Click the Gear icon on Load Data into table
- Select Use an Existing Table
- select your data store
- select your schema
- select your Table Name
- Load Mode: Insert New Rows Only
- Click Auto Map under the input column
- Select your ID field - NOTE: the Update key can never be NULL and must be unique
- Check Truncate Long Strings to Fit
- Save
- Save
- Name your Job
- You can now schedule your job.
For More Information:
- ETL: Scheduled Jobs Failing
- Java: Out of Memory Error - System Unavailable
- iDashboards Data Hub Manual 8. Extract, Transform and Load
- Java Documentation: 3.2 Understand the OutOfMemoryError Exception
If the above is unable to resolve the issue, then please contact iDashboards Support for further assistance.
Comments
0 comments
Please sign in to leave a comment.